Linking Italian Resources through the Linked Open Data Paradigm: The LiITA Project
One of the main challenges we face today is to make the huge amount of data and metadata stored in language resources interact on the Web in order to capitalise on the efforts spent in their development. This can be made possible through the application of the principles of the Linked Open Data (LOD) paradigm, a set of Semantic Web practices implemented through the description of resource (meta)data (including linguistic resources) using a model called Resource Description Framework (RDF).
The PRIN PNRR LiITA project aims to build the foundations of a LOD Knowledge Base of interoperable language resources for Italian.
Through the development of a Knowledge Base (KB), the LiITA: Linking Italian project will apply LOD principles to make the various Italian Language Resources interoperable on the Semantic Web.
The LiITA project architecture is inspired by the successful example of the ERC funded LiLa: Linking Latin project, which connects and makes resources for Latin interoperable.
The architecture of the LiITA KB will consist of a collection of canonical citation forms of Italian forms (lemmas), called the Lemma Bank: the occurrences of words in the corpora published in the KB, as well as the entries in the lexical resources, are made interoperable by linking them to their own lemmas.
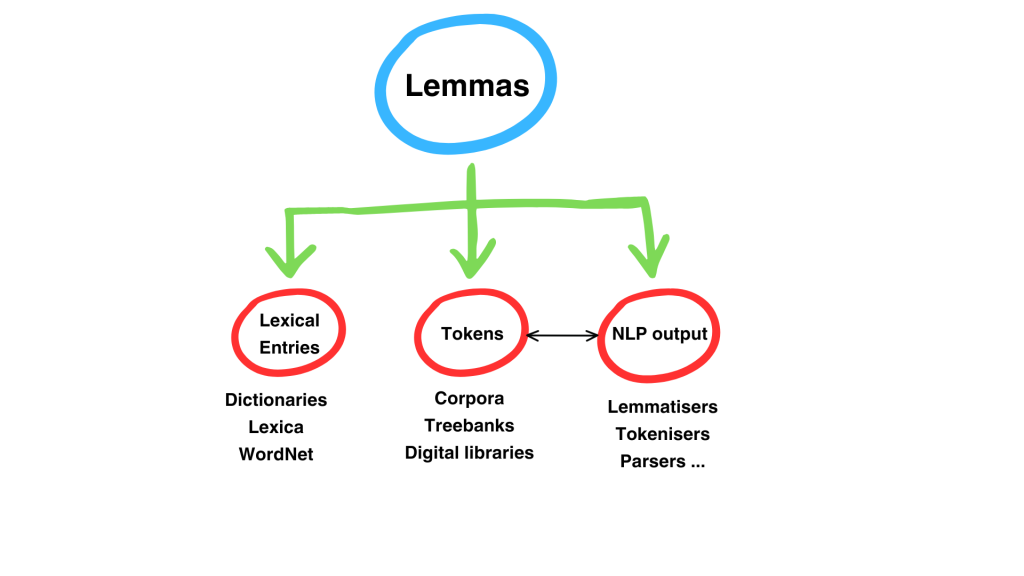
The (meta)data will be represented using knowledge description vocabularies (ontologies) widely adopted in the linguistic LOD community, such as OntoLex-Lemon (see bibliography here), an ontological model that allows for the description of entries in a lexical resource.
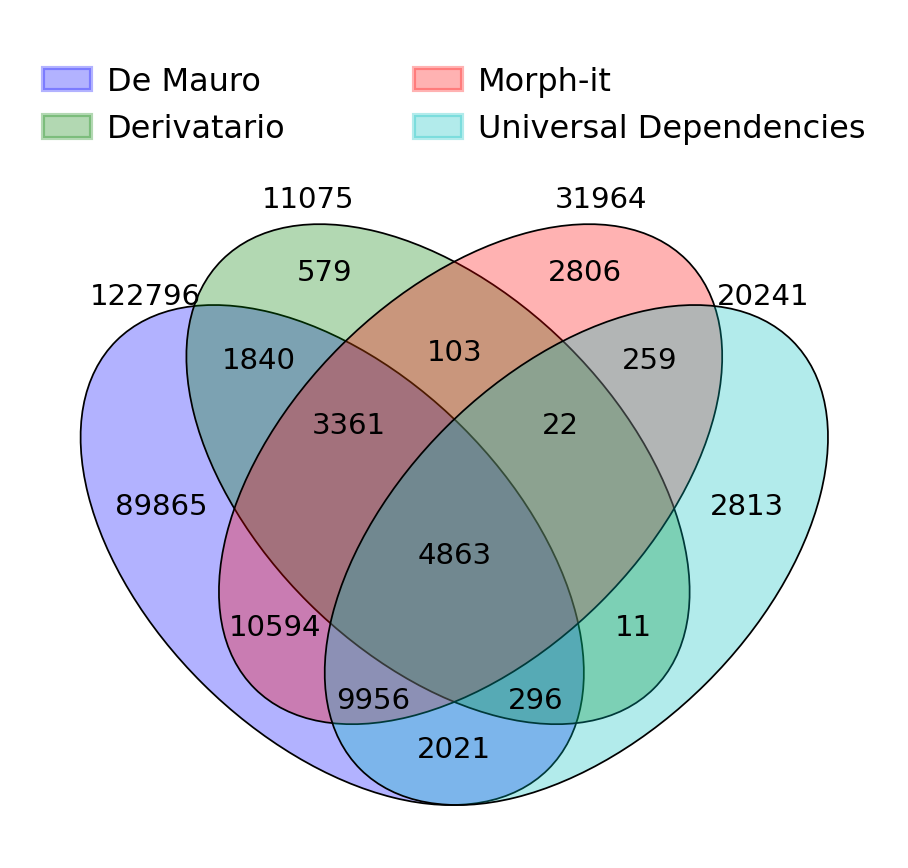
The Lemma Bank (currently under construction) is a formal representation model of lexicographic description consisting of 129,384 lemmas, coming from various existing lexical resources.
Follow the updates on the construction of the LiITA Lemma Bank here.
Select Bibliography
- Chiarcos, Christian, Nordhoff, Sebastian e Sebastian Hellmann. 2012. Linked Data in Linguistics. Heidelberg, Springer.
- Lassila, Ora / Swick, Ralph (1998). “Resource description framework (RDF) model and syntax specification”. http://www. w3. org/TR/REC-rdf-syntax/
- Passarotti, Marco / Mambrini, Francesco / Franzini, Greta / Cecchini, Flavio Massimiliano / Litta, Eleonora / Moretti, Giovanni / Sprugnoli, Rachele (2020). “Interlinking through Lemmas. The Lexical Collection of the LiLa Knowledge Base of Linguistic Resources for Latin”, Studi e Saggi Linguistici 58: 177–212.
- McCrae, John P. / Bosque-Gil, Julia / Gracia, Jorge / Buitelaar, Paul / Cimiano, Philipp (2017). “The Ontolex-Lemon model: development and applications”. In Proceedings of eLex 2017 conference: 19-21.
- Talamo, Luigi / Celata, Chiara / Bertinetto, Pier Marco (2016). “DerIvaTario: An annotated lexicon of Italian derivatives”. Word Structure 9: 72-102.
- Universal Dependencies: https://universaldependencies.org/
- Zanchetta, Eros / Baroni, Marco (2005). “Morph-it! A free corpus-based morphological resource for the Italian language”. In Proceedings of Corpus linguistics Conference Series 2005 (ISSN 1747-9398)