Milestone 1: Building the Lemma Bank
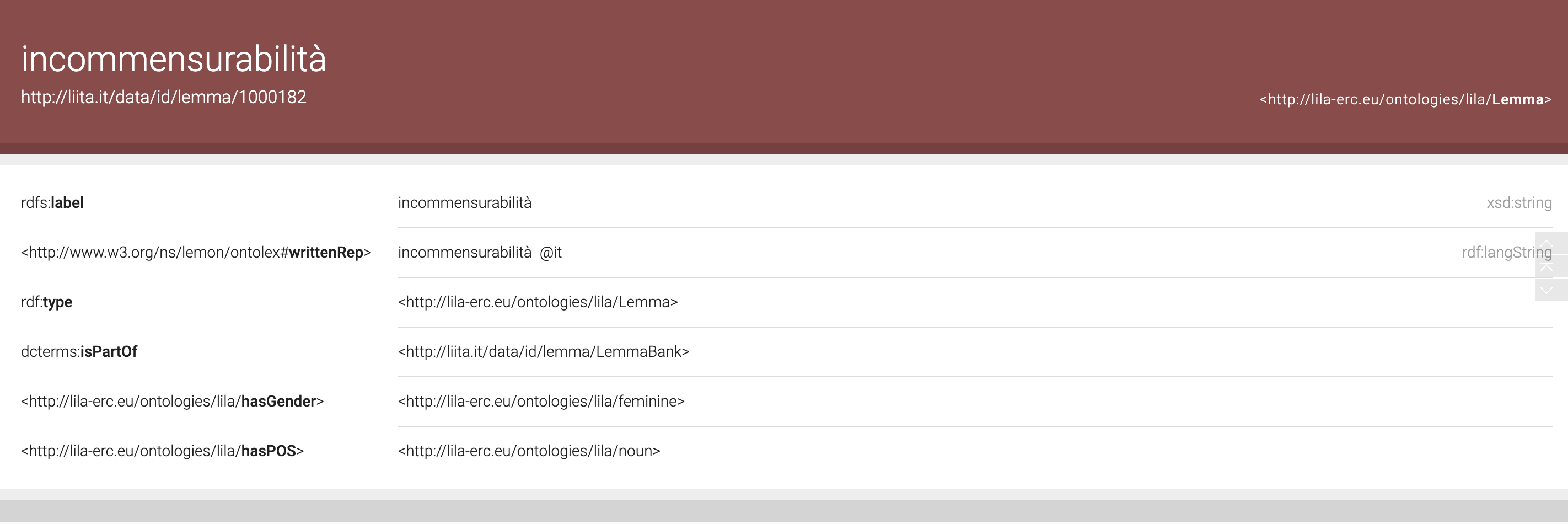
The first phase of the LiITA: Linking Italian project focusses on building a Lemma Bank from existing Italian lemma sets that will be meticulously selected and compared. The Lemma Bank is available as Linked Open Data, adhering to the widely accepted vocabulary outlined in the OntoLex-Lemon model for describing lexical resources:
- view: http://liita.it/data/id/lemma/LemmaBank
- download: https://github.com/LiITA-LOD/LiITA_LemmaBank
Access the data through our SPARQL endpoint.
Milestone 2: Linking the Resources
The second phase revolves around integrating a set of freely available Italian linguistic resources with the Knowledge Base. This includes one prominent lexical resource, specifically a WordNet, and one category of textual resources, in the form of the Italian treebanks available within the Universal Dependencies framework.
Milestone 3: Developing Tools
The project’s third phase brings forth the development of a tool that empowers resource providers to automatically connect their data to the Lemma Bank. Coupled with the project’s commitment to utilising established vocabularies for knowledge representation as LOD, this tool promotes an open-ended approach. As a result, the knowledge base becomes readily extensible and adaptable for future enrichment and expansion.
To ensure long-term sustainability and facilitate widespread dissemination, the project culminates with the integration of the Lemma Bank and its associated LOD resources into prominent infrastructures like CLARIN-IT and the European Language Grid. This final step guarantees the accessibility of the project’s valuable outcomes for the benefit of the wider research community.
Please check back to this page again soon to find more updates on the project’s data output.